Back in 2019, Nick Fitzgerald published always bump downwards, an article making the case that for bump allocators, bumping “down” (towards lower addresses) is better than bumping up. The biggest reasons for this are bumping up requires 3 branches vs 2 for bumping down and rounding down requires fewer instructions than rounding up. This became the method used for the popular bumpalo crate. In this post, I want to go back and revisit that analysis. If you have not read that article I recommend you do so, it is very well written.
Always bump downwards
First, let’s start with the code from the original article. I have modified the code to replace the try_mut! macro with NonNull.
Bump Down
impl BumpDown {
pub unsafe fn alloc(
&mut self,
size: usize,
align: usize,
) -> Option<NonNull<u8>> {
let ptr = self.ptr as usize;
let new_ptr = ptr.checked_sub(size)?;
// Round down to the requested alignment.
let new_ptr = new_ptr & !(align - 1);
let start = self.start as usize;
if new_ptr < start {
// Didn't have enough capacity!
return None;
}
self.ptr = new_ptr as *mut u8;
Some(NonNull::new_unchecked(self.ptr))
}
}
Bump up
impl BumpUp {
pub unsafe fn alloc(
&mut self,
size: usize,
align: usize,
) -> Option<NonNull<u8>> {
let ptr = self.ptr as usize;
// Round up to the requested alignment.
let aligned = (ptr.checked_add(align - 1))? & !(align - 1);
let new_ptr = aligned.checked_add(size)?;
let end = self.end as usize;
if new_ptr > end {
// Didn't have enough capacity!
return None;
}
self.ptr = new_ptr as *mut u8;
Some(NonNull::new_unchecked(aligned as *mut u8))
}
}
We can see the bump-up version has 3 branches (2 checked_adds and an explicit branch). Also, the code used to round up:
(ptr + (align - 1)) & !(align - 1)
Contains an extra addition compared to rounding down:
ptr & !(align - 1)
Reproducing the results
Let’s benchmark these two versions. Rather than having a single benchmark, I am going to break it into 4. We have allocating u8 (align=1, size=1), u64 (align=8, size=8), u128 (align=16, size=16), and byte slice (align=1, size=?). As you will see below, alignment has a big impact on the performance of a bump allocator. On my machine, the word size is 64-bits so most things will be aligned to that (which is why I picked u64 over u32). Each benchmark does 10,000 allocations.
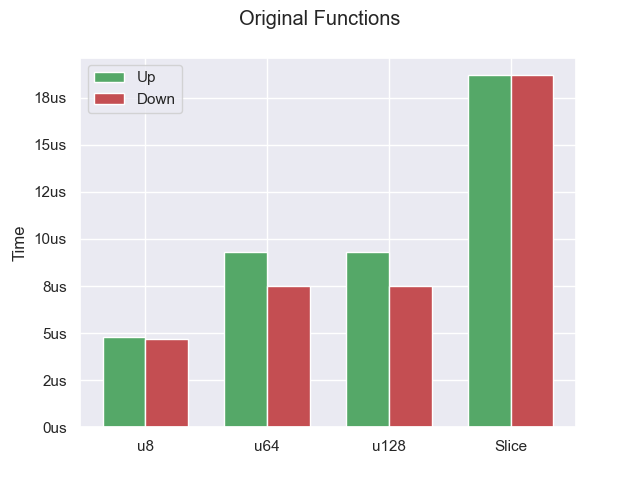
This matches the results from the original article. If we are allocating something that requires aligning (anything where align>1), then the bump-down code performs better than the bump-up version. For the remaining benchmarks, we are going to measure everything relative to this bump-down algorithm instead of providing runtimes.
Getting down to one branch
Okay now that we have done our due diligence and looked at the original result, let’s see if we can improve the bump-up allocator. The first thing is dealing with those two checked_add’s.
let aligned = (ptr.checked_add(align - 1))? & !(align - 1);
let new_ptr = aligned.checked_add(size)?;
if new_ptr > end {
return None;
}
Notice that the alloc function took size and align directly as usize. However, in a real allocator such as Bumpalo or anything using the Allocator API, you are accepting a Layout. Layout has an additional constraint on size and alignment that we can exploit:
size, when rounded up to the nearest multiple ofalign, must not overflowisize(i.e., the rounded value must be less than or equal toisize::MAX).
Following this rule, size and align must both be less than isize::MAX. And we know that isize::MAX + isize::MAX < usize::MAX. So instead of adding size and align directly to the bump pointer we can add them together and check that against the remaining space.
let offset = ptr.align_offset(align);
// can't overflow due to Layout constraints
let total_size = offset + size;
if total_size > end - ptr {
return None;
}
// we know that total_size + ptr <= end, so we can't overflow
let new_ptr = ptr + total_size;
let aligned = ptr + offset;
This reduces the number of branches when bumping up from 3 to 1 (which is less than bumping down, which requires 2). The bars below are all relative to the original bump-down alloc function.
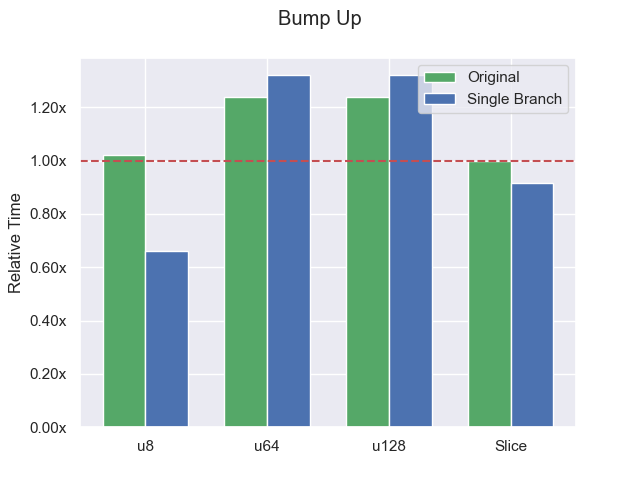
Removing those branches significantly helped when allocating bytes, but the extra addition penalized us in the aligned cases.
Alignment
You may have noticed that most of the code in the allocation function is there to handle alignment. If we are allocating word-aligned data (which includes most things in the standard library) then we need to recalculate the alignment for each allocation even though the bump pointer is already aligned from the previous one. Nick mentioned in his original article that we might be able to do “Less Work with More Alignment”. By requiring a certain minimum alignment, we can avoid having to align the allocation in many cases.
Let’s implement minimum alignment for bump up and set it to word aligned (8 in my case). This will allow the compiler to do any alignment calculations at compile time since alignment is almost always statically known.
#[inline(always)]
const fn align_offset(size: usize, align: usize) -> usize {
align.wrapping_sub(size) & (align - 1)
}
fn alloc(&mut self, layout: Layout) -> Option<NonNull<u8>> {
let ptr = self.ptr;
let align = layout.align();
let align_offset = if align > MIN_ALIGN {
Self::align_offset(ptr as usize, align)
} else {
0
};
let size = layout.size() + align_offset;
let available = self.end as usize - ptr as usize ;
if available >= size {
let end_offset = Self::align_offset(layout.size(), MIN_ALIGN);
let aligned_size = size + end_offset;
let result = ptr.wrapping_add(align_offset);
self.ptr = ptr.wrapping_add(aligned_size);
unsafe { Some(NonNull::new_unchecked(result)) }
} else {
None
}
}
This may look like more code, but when align <= MIN_ALIGN the align offset will be constant 0. In that case, the pointer to the start of the allocation is immediately available (in the bump-down case, the pointer always needs to be calculated). This helps with instruction-level parallelism since the processor has that data earlier. If the size is known at compile time, end_offset will be constant as well. If we are allocating a u64 this code will be reduced to something like this:
if (self.end - self.ptr) >= 8 {
let result = self.ptr;
self.ptr += 8;
Some(result)
} else {
None
}
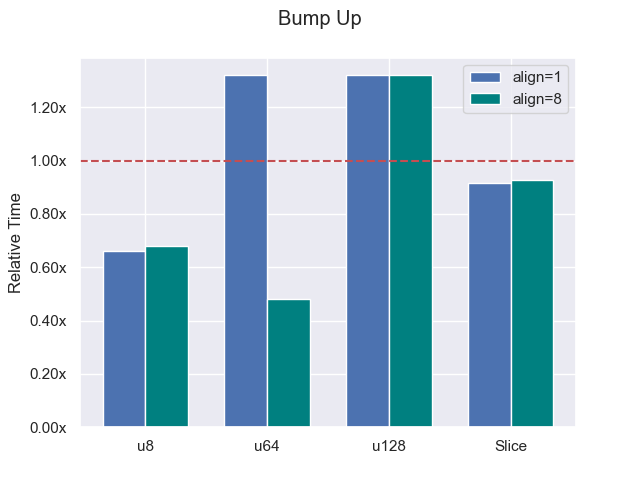
This is a huge improvement for the word-aligned case (u64). Now, it is not fair to only apply this optimization to bumping up, so let’s add it to bumping down as well.
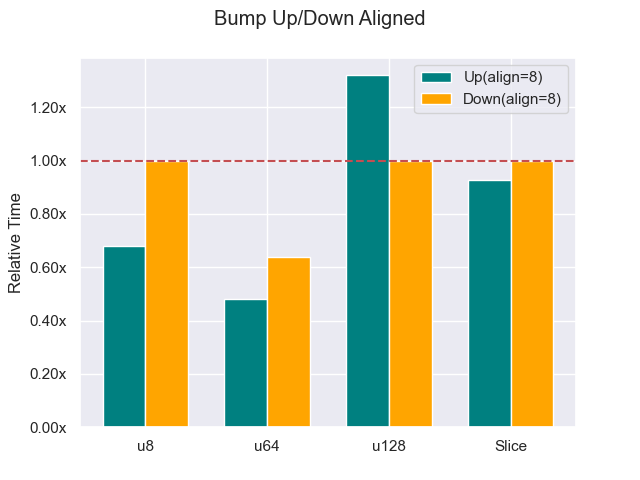
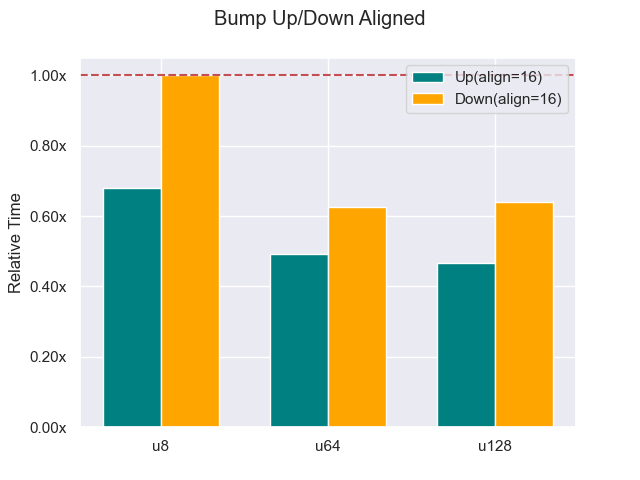
This also really helped the bump down for word alignment, but not as much as the bump up. When the alignment ≤ minimum alignment, bumping up can be much more efficient. However notice that in the u128 case, it does not help us at all. Thankfully, it is rare for something to need greater than word alignment. And we can see below that if we increase the alignment to 16 the bump up gains the advantage there as well.
The Natural Direction
My biggest takeaway from doing this deep dive is that I would argue that “bumping up” is the “natural” direction for allocation. Let me explain what I mean.
Reallocations
In the original article, it was mentioned that by bumping down you lose the realloc fast path. When reallocating (growing or shrinking) the last allocation with a bump allocator you can often do it in place. If we are changing the last allocation and there is room in the chunk you can just bump the pointer and avoid the need to allocate and copy.
This has many advantages when you are building some allocated data over time. Think pushing to a Vec or building a String with format!. You often don’t know the final size ahead of time so you tend to reallocate bigger and bigger chunks as the data grows. With forward bumping, you can often use that fast path and never copy the existing data. When you get to the final size you can use shrink_to_fit to return any unused space to the allocator and immediately reuse it. This is one of the major strengths of bump allocators.
You might expect bumping down to lose all these advantages, but Bumpalo can get the same space savings as a bump-up allocator. When it needs to grow an allocation in place (and it is the last allocation) it will bump the pointer down and overwrite the old allocation. It can do the same thing when calling shrink_to_fit (recopy the memory into a smaller footprint and reclaim the extra space). This means it doesn’t waste any more space than bumping up (which I think is a really neat trick!). However, it does still have the overhead of all that copying.
In the original article, it was mentioned that losing the realloc fast path only resulted in a 4% performance loss. Part of this is the design of that particular benchmark. It only allocates 13 bytes total, and only needs to copy 6 bytes for realloc, meaning that most of the benchmark time is dominated by other things. It is not pushing this to an envelope where we can see a real difference. I suspect that if you grew the benchmark further with larger allocations, the difference would be more pronounced.
Headers
There is another place where bumping up has a “natural” advantage. When declaring an unsized type in Rust, the sized portions of it have to go at the start.
struct InlineString {
len: usize,
capacity: usize,
data: [u8]
}
Since pointers to allocations are to the starting address, you can use the capacity field to see how much allocation is owned and where it ends. This is sometimes used in copying garbage collectors to create an “on heap” stack. You start with the first element, copy all of its children into the heap, and then use the header length information to jump to the next element. Once your tracing pointer reaches the allocation pointer, you are done with the collection. This means you don’t need a separate mark stack and avoids a level of pointer indirection. This doesn’t work when bumping down, because you can’t put the header at the end of an allocation, at least not without doing a bunch more gymnastics or only using raw pointers.
More optimizer friendly
Since bumping up tends to be simpler than bumping down, it gives more freedom to the optimizer. When I was first designing these benchmarks I had all allocations initialized to a constant value. When I ran the benchmark I found that the u8 benchmark was 8x faster for bumping up than bumping down. That didn’t smell right, so I looked at assembly and the optimizer was able to vectorize the allocations and do them 16 at a time! It did not vectorize the bump-down version, probably because of the extra branch. I repeatedly ran into issues where the optimizer would optimize the bump-up version so aggressively that it was no longer a fair comparison (and I would have to restrict the benchmark). That never happened with the bump-down version. How this would translate into real-world code is hard to say, but simpler code provides more opportunities for better code gen.
Should you bump up or down?
It is really hard to benchmark allocation in a vacuum because so much of the performance depends on what is being allocated and how much the optimizer can reason about it. But I think it is fair to say that bump-down does not have some absolute advantage in allocation. As with everything in engineering, it is all about trade-offs. All though picking a good minimum alignment benefits both allocators, bump-up is more sensitive to it than bump-down is. Bump-up also lets you keep the realloc fast path. If you use word alignment, bumping up will be the optimal strategy the majority of the time.
You can find the benchmarks used in this article here.
Have a comment?
Join the discussion on HN, Lobsters, Reddit, or send me an email.