In this post, we are going to take a deep dive into pointer tagging, where metadata is encoded into a word-sized pointer. Doing so allows us to keep a compact representation that can be passed around in machine registers. This is very common in implementing dynamic programming languages, but can really be used anywhere that additional runtime information is needed about a pointer. We will look at a handful of different ways these pointers can be encoded and see how the compiler can optimize them for different hardware. Because untagging a pointer is usually just a few instructions, it normally won’t show up in a traditional profiler. But billions of these operations can add up to make a difference in the total runtime of a program.
The types of tagged pointers
We will be testing 4 different types of tagged pointers here:
- Lower bits
- This is probably the most common type of tagged pointer, and the one used by Emacs. Essentially this takes advantage of the fact that pointers are usually aligned to a machine word, so on a 64-bit platform there are 3 bits at the bottom of the ptr that will always be 0. These can be used to tag the value without impacting the pointer at all.
- Lower byte
- Not only is there empty space at the bottom of a pointer due to alignment, but there is also (usually) space at the top. Most modern 64-bit machines do not use the full 64 bits of address space, leaving the top 2 bytes unused1. Lower byte tagging takes advantage of this by shifting the value up one byte and using the bottom byte as a tag. The idea is that accessing the bottom byte is easier than the top byte for most instruction sets. This gives a much larger range of tags.
- Upper byte
- similar to lower byte, but the tag is stored in the top of the word instead of the bottom. This would allow you to take advantage of hardware support for Top Byte Ignore (TBI) to untag the pointer for free. Currently, ARM is the only major vendor with support for TBI. Android even uses this for extra levels of security. In the benchmarks below we are not using TBI.
- Upper bits
- This tagging scheme also takes advantage of the alignment bits at the bottom of the pointer but stores the tag at the top. The pointer is right-shifted by the number of alignment bits before inserting the tag. This allows us to use multiplication to retrieve the value, which can be directly embedded into the instruction stream.
- Nan Boxing
- Generally used only in languages where floating points are the primary number (such as Javascript and Lua). This scheme takes advantage of the fact the IEEE floating point number has a bunch of unused values to represent NaN (Not a Number) and these can be used to encode pointers. This allows us to embed floats directly into the tagged value without having to dereference a pointer.
We will be testing against a fat pointer for the baseline. This will use two words, one for the tag and one for the pointer. This is what you get with Rust enums or Zig tagged unions. Since this version does not need to do any pointer manipulation for untagging, we expect it to be faster than the tagged pointers.
| type | create | get tag | get data | total tags |
|---|---|---|---|---|
| lower bits | ptr | tag | ptr & 0x7 | ptr & !0x7 | 8 |
| lower byte | ptr << 8 | tag | ptr as u8 | ptr >> 8 | 256 |
| upper bits | ptr | tag << 61 | ptr >> 61 | ptr << 3 | 8 |
| upper byte | ptr | tag << 56 | ptr >> 56 | ptr & !(0xFF << 56) | 256 |
| nan boxing | ptr | nan | tag | if nan == (ptr & nan) {ptr & 0x7} | ptr & !(nan | 0x7) | 8 |
In theory, these should all be roughly the same, as they each use one operation to get the tag and another to get the data. But as we will see below, that is not always the case and even depends on the instruction set used.
We have two main flavors of benchmarks:
- Check tag
- Only check if the pointer matches a certain set of tags and if so increment a counter. This lets us benchmark just the “untagging” portion without dereferencing the pointer.
- Get data
- Untag the pointer and if it matches the tags of interest add the value to a rolling sum. All the tagged data types have an integer field used for this benchmark, but the field is not always at offset 0.
Each benchmark consists of 10,000 iterations. Benchmarks are run on an ARM M1 MacBook unless it says otherwise.
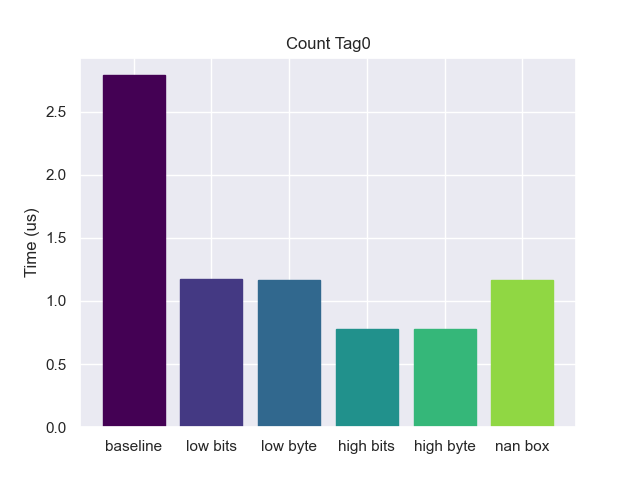
Tag 0
Starting off with a benchmark to sum all items that have a tag value of zero.
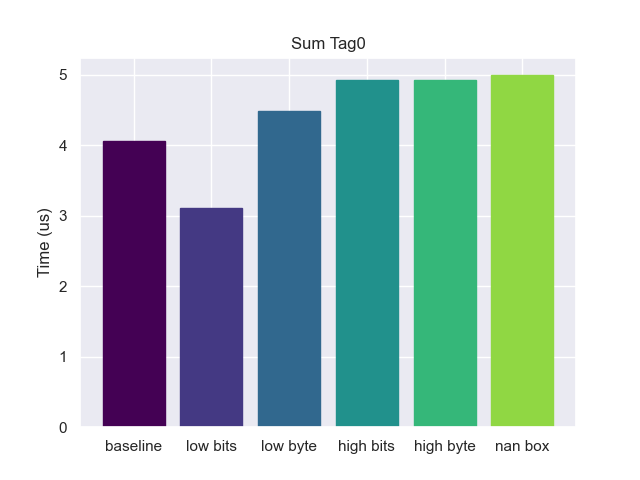
We can see from the benchmarks above that alignment bit tagging did really well. With this particular tag, the compiler is able to do several clever optimizations. The first is with checking the tag. We would expect it to do a bitwise and followed by a compare
;; x86 asm
and edx, 7
cmp dl, 0
But it is able to use the test instruction, which both masks and compares to zero at the same time.
;; x86 asm
test dil, 7
Since the tag is 0, there is nothing to remove from the lower part of the pointer so it can be dereferenced without any extra instructions. This essentially has no overhead, even beating out the baseline (probably due to a more compact representation). But these optimizations are taking advantage of the special properties of zero, what happens with other tags?
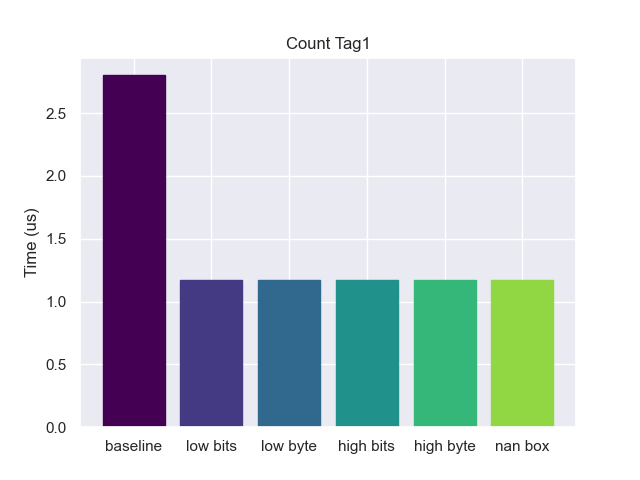
Tag 1
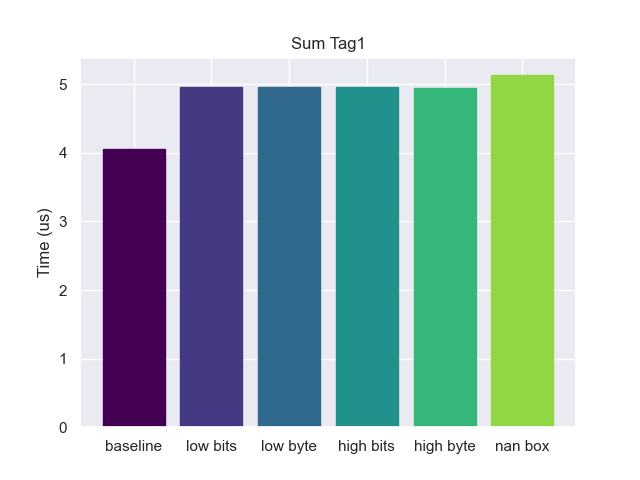
Once we are no longer dealing with tag zero, alignment tagging is effectively identical to the rest. We can no longer use the cmp trick to check the tag in a single instruction, instead needing to and then cmp. But also we now have to mask out the tag in the bottom of the pointer before we dereference (adding another instruction). However, there is a way that we could avoid that.
If we are not accessing the first field of data then we will load the pointer with an offset. The assembly looks like this:
;; x86 asm
and rdi, -8 ;; Mask out the tag in the low 3-bits
mov eax, dword ptr [rdi + 4] ;; load the field at offset 4
Rather than masking with and we could instead turn this into a subtract (e.g. if the tag is 1, then subtract 1 one from the pointer). This subtraction could then be folded into the load and become a single instruction:
;; x86 asm
;; Combine the tag removal with the pointer load
mov eax, DWORD PTR [rdi + 3]
Interestingly, clang/LLVM will not do this optimization, even if you explicitly use subtraction in the code (it will always convert it back to an and). However, GCC will happily do this optimziation. This makes the GCC version of the sum benchmark about 20% faster than the LLVM version in the cases where this is applicable. My best guess is that there is some peephole optimization in LLVM that is doing a “strength reduction” to convert some subtractions to and’s, which is ruining its ability to merge it into the load. Compilers are complicated 2.
x86
As I teased at the start, some of the benchmarks are ISA-specific. Let’s take the same Tag 1 value benchmark and run it on x86 (Intel I7-14700K).
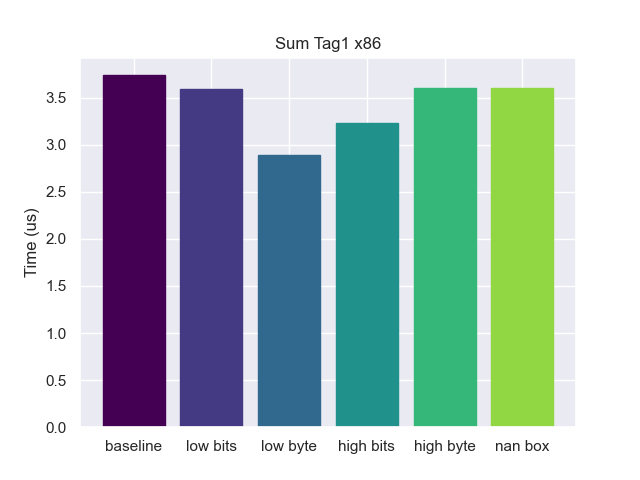
While all options were essentially the same on ARM, here we see low-byte tagging is significantly faster. Why is that? It comes down to differences in the instruction set. In x86 you have direct access to the low byte of a 64-bit register via a separate *l register (for example to access the low byte of edx you would use dl). This means that x86 can untag a low-byte pointer without any extra instructions. But on ARM ISA the only way to access the low byte is via a mask. Here is another benchmark using tag 7 showing the same behavior.
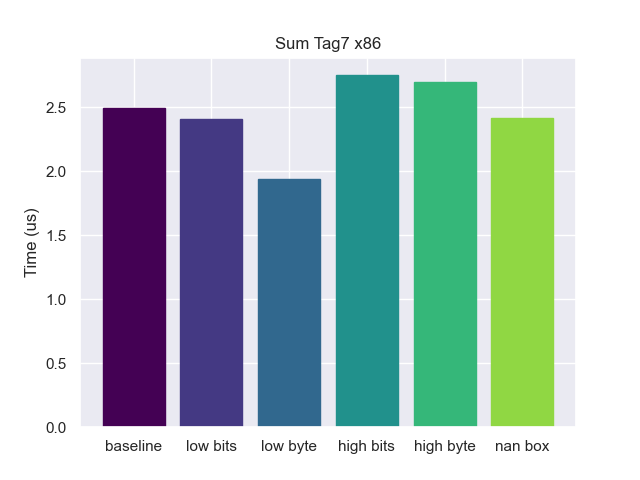
Tags 2-7
The results for all the rest of the tags are the same as tag == 1 (at least on ARM). This is kind of expected, since zero is a special value that lets the compiler do more optimizations, but none of the other numbers are special, so I am going to leave them out.
Check Tags
With these benchmarks, we are just testing the operation to extract the tag value (we do not dereferencing the pointer). This gives more room to the optimizer and has some interesting differences between the tagging schemes.
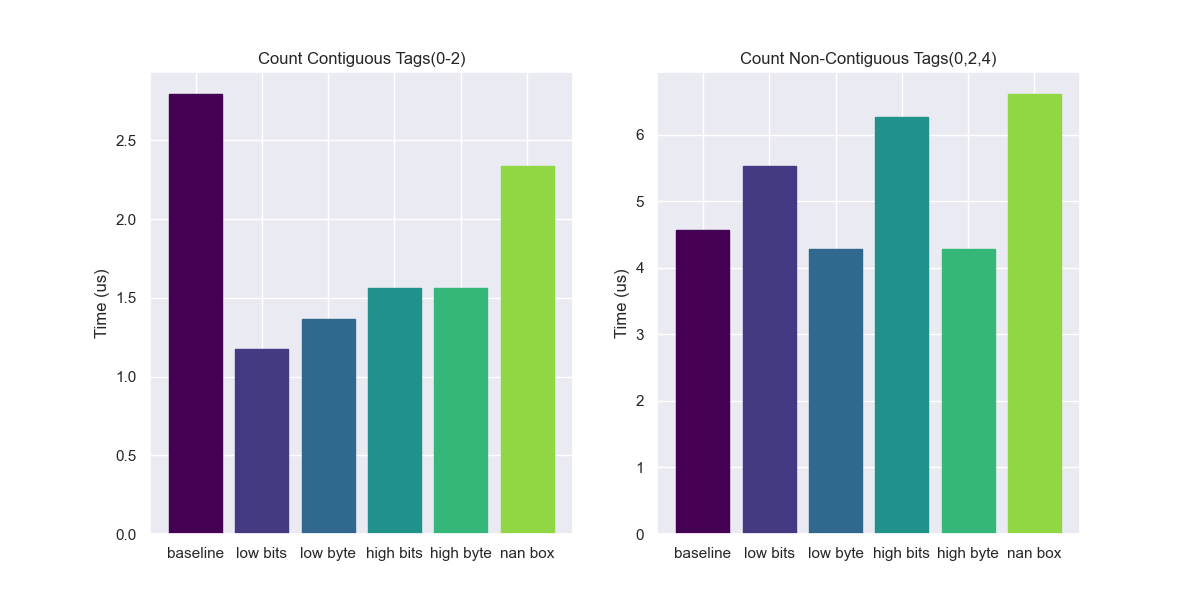
Here we see the opposite of the benchmarks above. The high-bit schemes beat out the low-bit ones. The reason for this is that the optimizer is able to vectorize this operation and can use the SIMD CMHI (compare unsigned high or equivalent in SSE) function to check multiple high tags at the same time. But once again this difference goes away once we are not checking for tag 0.
Also, notice that the tagged versions are significantly faster than the baseline here. This is because the baseline is two words wide but only one of them contains the tag. This prevents auto-vectorization of the baseline value, making it slower than the tagged versions. The compiler will even auto-vectorize checking for multiple tags so long as they form a contiguous range. But if there are gaps in the tags we are checking for we lose the ability to vectorize the code.
Below is another example of how different architectures can impact the results:
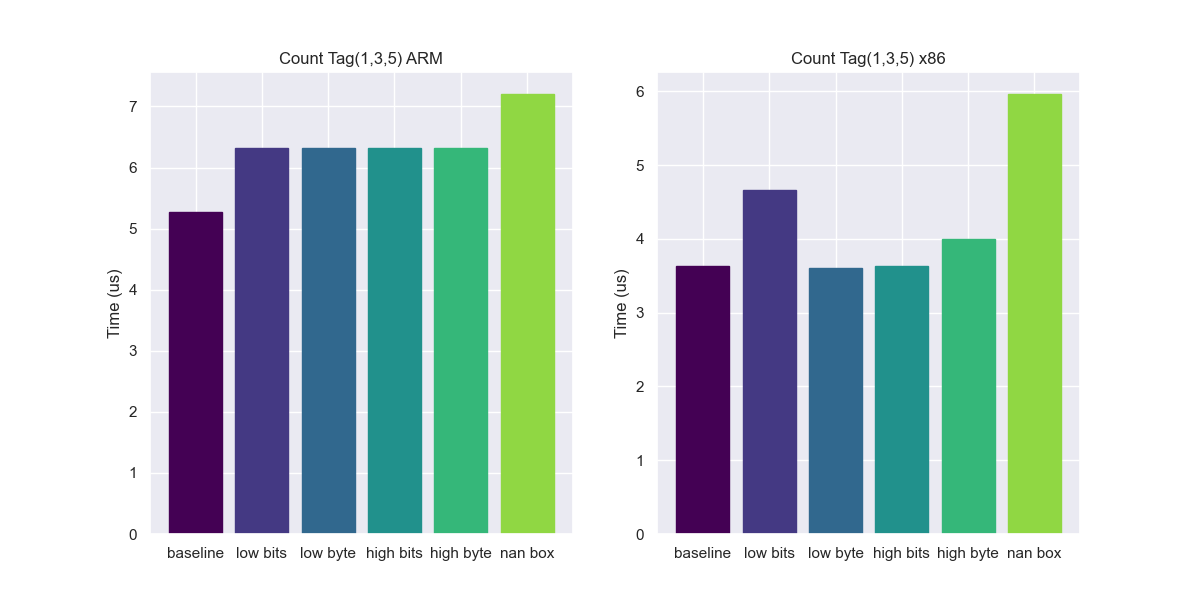
All the methods except for nan-boxing are the same on ARM, but on x86 low-byte and high-bits can be as optimized as the baseline. I didn’t dig into the discrepancy here.
Function calls
Generally, untagged pointers are faster than tagged ones. But sometimes the smaller size also leads to performance advantages as we saw above. One place where this shows up is in function calls. Once the number of arguments goes beyond a certain size the program will have to start spilling arguments to the stack. Since non-tagged values are twice the size of tagged ones, they will hit this condition earlier. Take the benchmarks below, where we compare calling with 7 arguments vs 8.
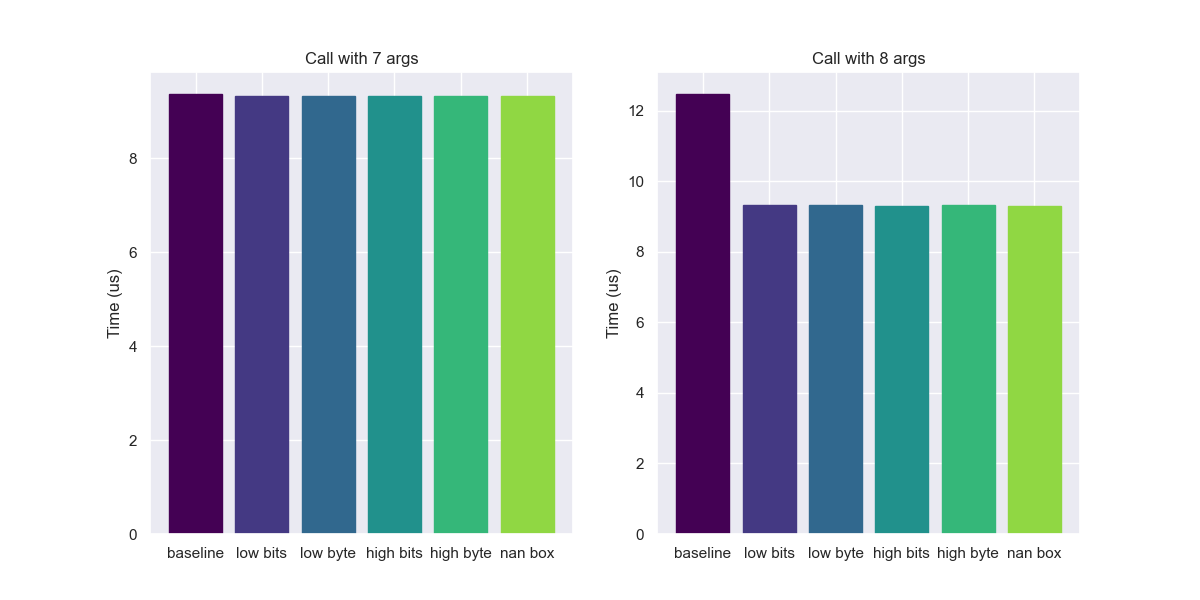
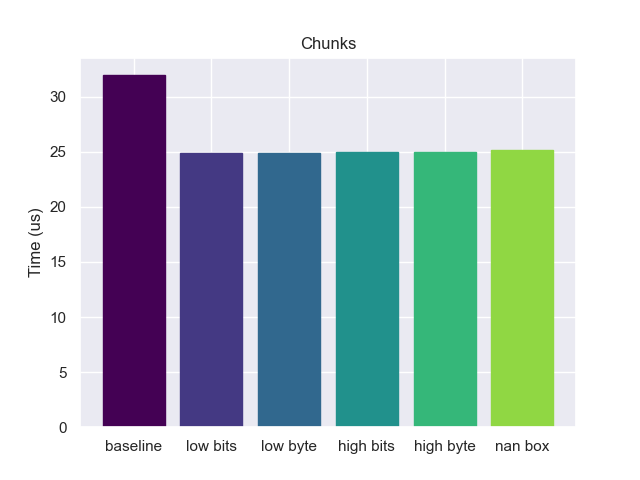
Or consider this bulk test, which rather than operating on one item at a time works on a chunk of 8. The larger size leads to slowdowns relative to the tagged values.
Eliding pointer tagging
There can be an interesting interaction when we tag a pointer and then immediately untag it when writing an interpreter. This might happen due to inlining or JIT compiling some code. In this case, we would hope that the compiler is able to elide the tagging/untagging operation and just use the value directly. How does this actually play out?
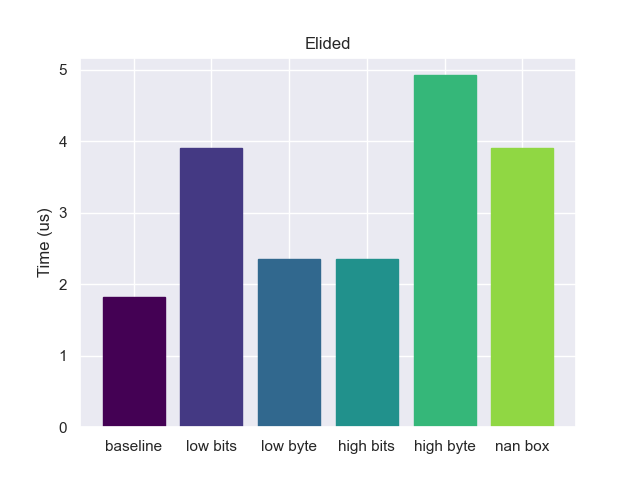
The only method that is able to completely elide the tagging is the baseline, all others have some extra instructions. If we step back this makes sense. When we or the tag into the pointer, the compiler doesn’t know that the bits were originally 0, so it has to assume that the value might be some combination of our tag and previous bit pattern. However, we know that the places where we are storing our tags will always be zero. If we communicate that to the compiler via hints:
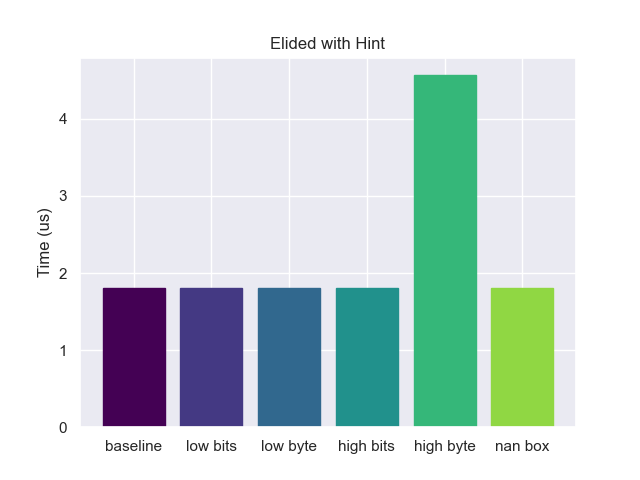
The compiler was able to completely elide all tagging operations except for High Byte tagging. For some reason, I was never able to get the compiler to understand that one.
But what about floating point?
It seems like we should have a benchmark to compare floating point math so we can see where nan-boxing really shines. However, that is not something that is easy to create a microbenchmark for. The benefit of nan-boxing is that we don’t have to dereference a pointer to get the float. But dereferencing a pointer is not in and of itself an expensive operation. What is expensive is a cache miss. If the floating-point value is in the cache then it will be fast to access, but if it is out of the cache it could take hundreds of cycles to fetch it. So the benefit of nan-boxing can range from negligible to game-changing. This can’t be captured in a microbenchmark because the way they are structured is to keep the cache hot. But if floats are a big part of your data structures, then nan-boxing will be the winner every time, despite being slightly slower on some of the operations above.
So which is best?
As we mentioned above with nan-boxing, in almost all modern systems the limiter on system performance is memory, not CPU instructions. Some of the tricks explored above could save 1 or 2 instructions in some circumstances, but a single cache miss could have your CPU waiting for hundreds of cycles. Architecting your system to avoid pointer chasing and cache misses will almost always be more impactful than trying to save a few cycles in your tagged pointer scheme. So in a sense, these benchmarks are really optimizing for the wrong thing.
On top of that, in the “general case,” these schemes are all the same. They all take 1 instruction to get the tag and one to untag the pointer. There are particular circumstances, compilers, and ISAs where things can be optimized away as we saw above. But those are exceptions, not the rule. If you took an existing system and switched the pointer tagging scheme I would not expect to see any measurable difference. As with any performance-related changes, you should benchmark your workloads and see if they actually make a difference for you. The benchmarks here were designed to exaggerate the differences between schemes by not doing any meaningful work and keeping everything in the cache. A 20% difference in a microbenchmark is not going to be as large in a bigger workload.
There are other non-performance differences between the tagging schemes. The most obvious is the total number of tags. Alignment tagging can only support 8 total tags (on 64-bit machines). Using a whole byte gets you 256 tags. Given what we discussed above about memory being the bottleneck, not having to do a memory access to check the tag is a big benefit! Conversely, using fewer bits for the tag means you have more bits for the data. This enables you to store large integers, floats, and even small strings inline.
Also, you need to consider how portable the tagging scheme needs to be. You may not always be able to assume that the high bits of a pointer will be unused. If the kernel is using TBI then you can’t touch that part of the pointer. If you need maximum portability, alignment tagging can be used on almost any architecture.
And these are not even all the possible ways to tag a pointer! There are all sorts of tricks you can use with integers to pack in more information or access it faster. See this paper, for deep dive into all things tagged pointer, including staged tagging, dispatch techniques, and tagged arithmetic. After reading that you will see that we haven’t even begun to scratch the surface here.
Either way, this was a fun exploration into how compilers and ISA can have an impact on generated code and performance. I started this with the expectation that I would be able to find the “best” pointer tagging scheme empirically. But as with so many things in engineering, it turns out the real answer is “it depends”.
Have a comment?
Benchmarks can be found here.
Join the discussion on HN, Lobsters, Reddit, or send me an email.
-
I say unused, but not necessarily zero. On Linux in particular the top bytes are 1 if the pointer is in kernel space. ↩︎
-
An LLVM contributor pointed me to this modified version of the code where LLVM will do the optimization we want. The key change is subtracting 1 instead of
tag. Even though we “know” that the tag is 1 inside theifstatement, compilers sometimes struggle with control flow-dependent facts. ↩︎